
Meta, encabezada por Mark Zuckerberg, ha revelado su última creación: una inteligencia artificial capaz de interpretar más de mil idiomas. En un emocionante avance tecnológico, la compañía ha presentado nuevos modelos que superan significativamente a los sistemas existentes en términos de reconocimiento y reproducción de idiomas.


Una inteligencia artificial con miles de fuentes
Con una capacidad diez veces mayor que sus predecesores, estos modelos han sido entrenados utilizando una amplia variedad de fuentes, incluida la biblia, por parte de talentosos desarrolladores. Esta innovadora IA promete abrir nuevas fronteras en la comunicación global y acercar aún más a las personas de todo el mundo.
Meta ha dado a conocer su último avance en inteligencia artificial: nuevos modelos capaces de reconocer y reproducir el habla en más de 1,100 idiomas. Esta capacidad es diez veces superior a la ofrecida por tecnologías similares disponibles en el mercado, según afirmó la compañía en un comunicado. Lo destacable de esta iniciativa es su enfoque en la preservación de idiomas en peligro de extinción.
Bajo el nombre de Massively Multilingual Speech (MMS), estos nuevos modelos han sido puestos a disposición del público a través de GitHub, una plataforma de alojamiento de código. Meta ha subrayado que, al lanzarlos como código abierto, se facilita a los desarrolladores la creación de nuevas aplicaciones de voz que promuevan la inclusión en un sentido más amplio.
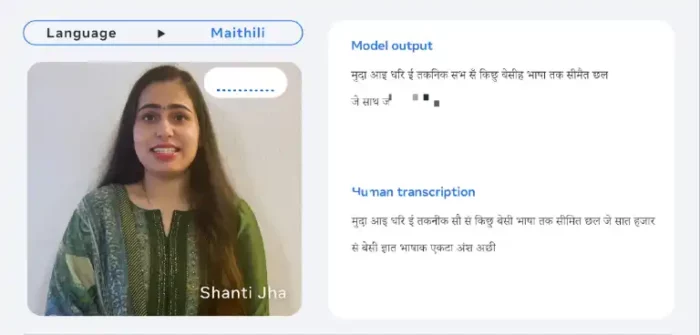

Convertir voz a texto y viceversa
Los recientes modelos presentados tienen la capacidad de convertir texto en voz y viceversa en más de 1,100 dialectos, pero su potencial va más allá, ya que son capaces de reconocer más de 4,000, lo que supone una mejora significativa de 40 veces en comparación con los sistemas previos.
Aunque existen aproximadamente 7,000 idiomas en el mundo, las herramientas convencionales de reconocimiento de voz solo reconocen alrededor de 100. Estos sistemas suelen requerir grandes cantidades de datos de entrenamiento etiquetados, como transcripciones, los cuales solo están disponibles para algunos idiomas, como el español, el inglés y el chino.
Esta limitación ha sido un desafío en el desarrollo de tecnologías de reconocimiento de voz inclusivas y precisas. Para desarrollar la inteligencia artificial capaz de interpretar más de mil idiomas, Meta utilizó un modelo de IA que habían desarrollado en 2020.

IA multiidiomas
Este sistema ya tenía la capacidad de aprender patrones de voz a partir de archivos de audio, sin requerir grandes cantidades de datos etiquetados, como transcripciones. La compañía, casa matriz de Facebook e Instagram, empleó dos conjuntos de datos nuevos para este proyecto.
El primero consistía en grabaciones de audio junto con el texto del Nuevo Testamento de la Biblia, obtenido de Internet en 1,107 idiomas diferentes. El segundo conjunto de datos contenía grabaciones de audio sin etiquetas del Nuevo Testamento en 3,809 dialectos, según reportó MIT Technology Review.
Los investigadores de Meta utilizaron un algoritmo diseñado específicamente para alinear las grabaciones de audio con el texto correspondiente. Luego, repitieron este proceso con otro algoritmo, entrenado con los datos previamente alineados. De esta manera, el equipo logró entrenar al algoritmo para aprender nuevos idiomas de manera más sencilla, incluso sin la necesidad del texto como referencia.


Meta llevó a cabo una comparación entre sus modelos y los de OpenAI Whisper, así como otros competidores. Según asegura, su modelo presenta la mitad de la tasa de error, a pesar de abarcar 11 veces más idiomas.
“Ahora somos capaces de construir sistemas de voz con una cantidad mínima de datos de manera muy rápida”, explicó Michael Auli, científico involucrado en el proyecto, en una entrevista con el MIT.
No obstante, los investigadores advierten que estos modelos de lenguaje impulsados por inteligencia artificial aún pueden cometer errores al transcribir ciertas palabras o frases. En la práctica, esto puede dar lugar a etiquetas imprecisas o potencialmente ofensivas.




