Google ha dado a conocer su nuevo modelo de inteligencia artificial (IA) para generación de imágenes, Imagen 3. Sorprendentemente, el gigante tecnológico optó por un lanzamiento discreto, sin realizar ningún anuncio oficial.
En paralelo, se publicó un artículo de investigación que detalla el funcionamiento del modelo. Por el momento, Imagen 3 está disponible exclusivamente para usuarios en Estados Unidos, aunque, desde mi experiencia, he podido usarlo sin estas limitaciones desde México.


Imagen 3: mejoras y limitaciones
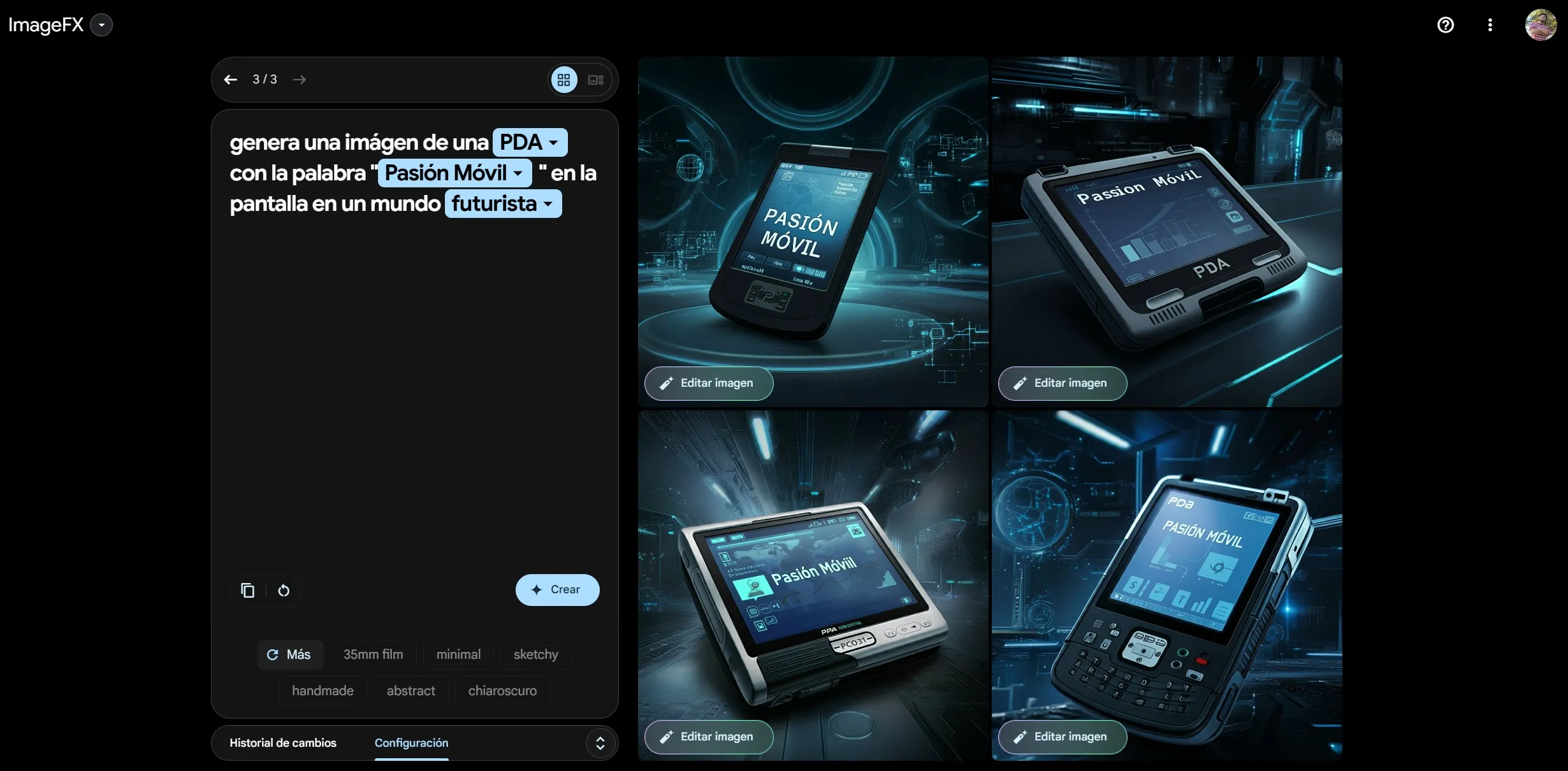
A través de su plataforma AI Test Kitchen, Google permite a los usuarios registrarse y experimentar con Imagen 3. Esta tercera generación del modelo presenta avances significativos en la generación de texturas, reconocimiento de palabras y congruencia con las indicaciones proporcionadas.
Aunque no es posible para muchos realizar pruebas directas debido a la restricción geográfica, he tenido la oportunidad de crear imágenes proporcionando instrucciones en inglés y también en español con resultados favorables.
Sin embargo, el modelo presenta dificultades en la creación de imágenes cercanas con múltiples personas y en condiciones de poca luz, áreas en las que su predecesor mostraba mejores resultados.
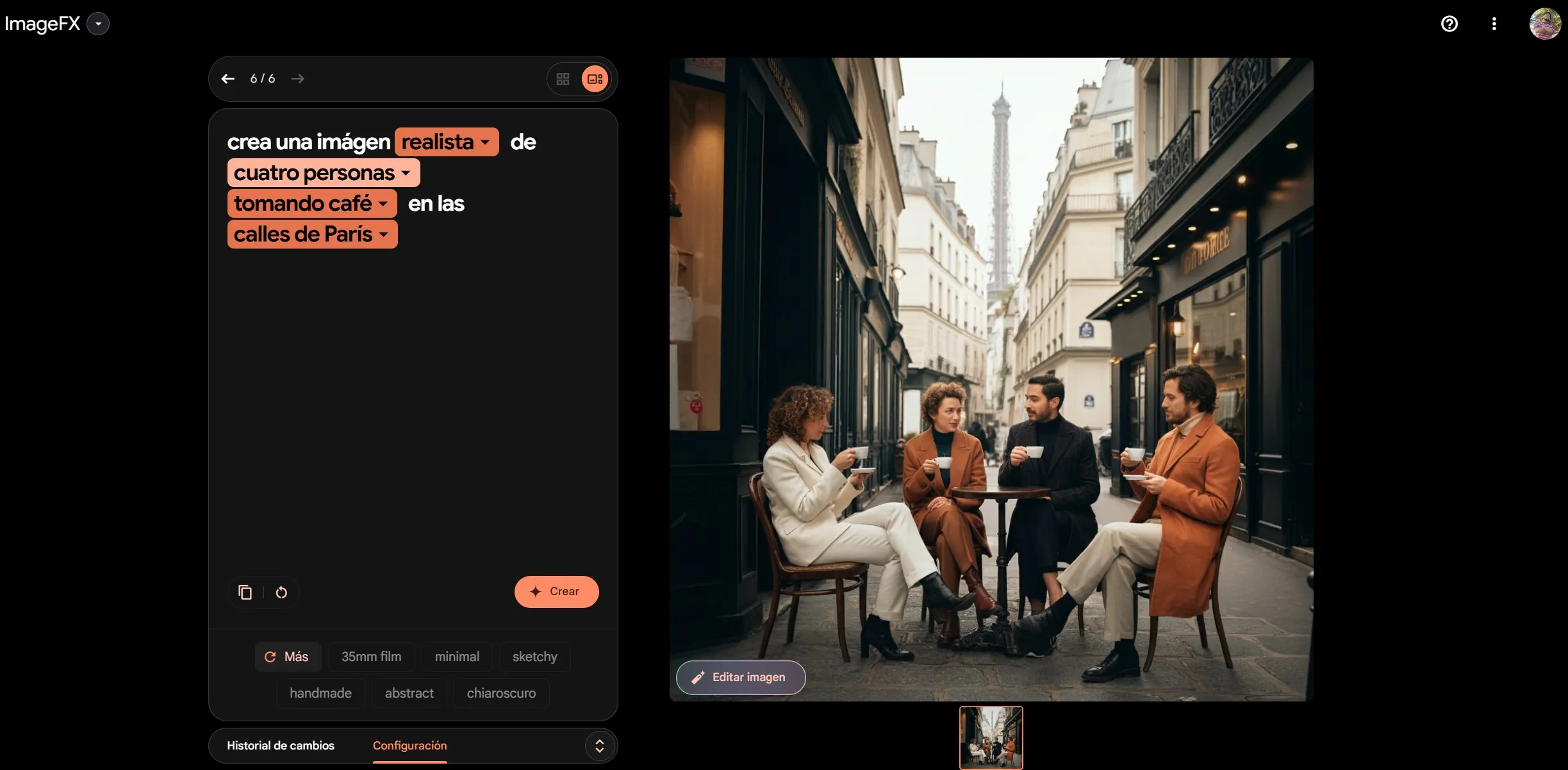

Otro desafío identificado es la generación de extremidades humanas. El modelo tiende a producir resultados erróneos cuando se le solicita representar a una persona sosteniendo un objeto, como una taza de café.
En algunos casos, se añaden extremidades adicionales, se crean miembros aleatorios que sostienen el objeto o se fusionan el objeto con la extremidad. Además, se reporta una censura estricta en las indicaciones proporcionadas al modelo.
Desde mi perspectiva, solo he tenido problemas al solicitar imágenes en las que indico el nombre de algún personaje específico, por ejemplo, Elon Musk, Steve Jobs, etc., indicando un problema con los términos de uso de este modelo de IA.

Detrás de Imagen 3: tecnología y mitigación de riesgos
Google ha publicado un artículo de investigación en la plataforma arXiv, donde detalla el uso de un modelo de difusión latente como base para Imagen 3. Esta técnica, popularizada por Stable Diffusion, ha sido adaptada para minimizar los posibles riesgos asociados con el uso del modelo.
Es importante destacar que, si bien la versión gratuita del chatbot Gemini también puede generar imágenes, lo hace utilizando las capacidades propias de Gemini.
Este software se basa en una arquitectura diferente y ha sido entrenado específicamente con un conjunto de datos compuesto principalmente por imágenes, lo que le confiere una mayor habilidad en esta tarea.
Fuente: Google

-

-

-

-

