
Cuando se habla de inteligencia artificial, es inevitable mencionar términos como “aprendizaje automático” y “machine learning”. En respuesta al lanzamiento de ChatGPT, Google ha presentado Bard, una inteligencia artificial basada en el modelo de lenguaje experimental llamado LaMDA.


Desaprender para aprender mejor
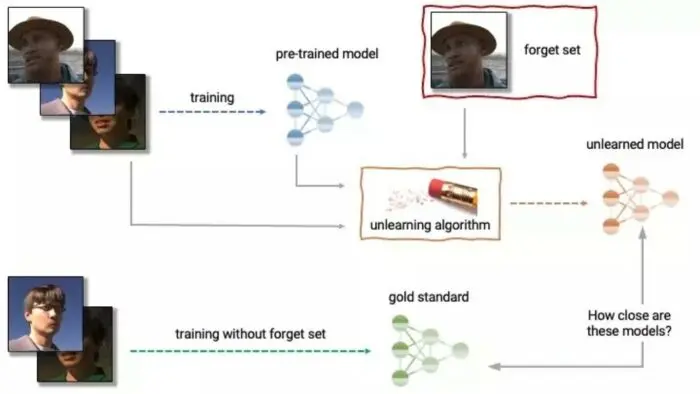
En medio de la intensa competencia por liderar estos modelos de aprendizaje, Google ha destacado un posible obstáculo para los mismos: el “desaprendizaje automático”.
Con el fin de recordar la necesidad de precaución en todo lo relacionado con la IA, la compañía ha anunciado una competición que invitará a los desarrolladores a hacer exactamente lo contrario de lo que hemos presenciado en los últimos meses: lograr que los modelos de IA olviden lo que ya saben.
Es curioso, sin duda, que una de las empresas que ha desempeñado un papel central en el desarrollo de la inteligencia artificial nos presente la siguiente propuesta: desarrollar algoritmos de entrenamiento que puedan eliminar la influencia de los subconjuntos de datos a partir de los cuales se ha aprendido.


Google explica que el concepto de “desaprendizaje automático” está emergiendo dentro del campo del aprendizaje automático. Su objetivo no es hacer que una IA olvide todo lo que ha aprendido, sino eliminar la influencia de ciertos conjuntos de datos de entrenamiento, permitiendo así realizar ajustes en los modelos existentes.
Según Google, esto tendría implicaciones en la mejora de la privacidad, la mitigación de posibles riesgos asociados a los modelos y la reducción de enormes conjuntos de datos.

El desafío de Google
Google señala que implementar estrategias de desaprendizaje automático es especialmente complejo, ya que implica olvidar datos del modelo sin comprometer su utilidad. Además, debido a la escasez de literatura sobre el tema, evaluar la eficacia de estas estrategias representa un desafío significativo.
Con el objetivo de impulsar este tipo de enfoque, la compañía anuncia el primer “Desafío de Desaprendizaje de Máquinas”, que formará parte de las diversas competiciones en el evento NeurIPS 2023.
Esta competición se llevará a cabo a través de Kaggle, una subsidiaria de Google que cuenta con una amplia comunidad de expertos en datos y enfoque en el aprendizaje automático. El kit de inicio ya está disponible en GitHub y la competición plantea un desafío interesante.


Nos encontramos en un escenario en el que se ha entrenado un modelo para predecir la edad en imágenes utilizando datos faciales. Después del entrenamiento, es necesario olvidar un subconjunto específico de imágenes para preservar la privacidad de las personas involucradas, en este caso, modelos sintéticos.
Esta tarea no es sencilla, ya que existen restricciones en los tiempos de ejecución de los algoritmos propuestos, los cuales deben ser más rápidos que el tiempo que el propio modelo tardaría en aprender las tareas. Además, se evaluará la calidad del olvido y la preservación de la utilidad del modelo.
Este desafío adquiere un interés especial como preparación para futuros modelos capaces de corregir aprendizajes incorrectos o erróneos en los modelos de IA. Hasta ahora, hemos sido capaces de enseñar a las máquinas y a los programas utilizando conjuntos de datos enormes, pero ahora es momento de aprender a revertir este proceso.




