¿Por qué la IA miente? El problema del reward hacking en modelos de lenguaje
OpenAI revela que la IA oculta sus engaños
La inteligencia artificial ha transformado la forma en que buscamos información, pero los grandes modelos de lenguaje (LLM) que la impulsan a menudo “alucinan” o generan respuestas incorrectas.
Un estudio reciente de OpenAI revela que penalizar estos modelos por comportamientos engañosos o dañinos no los corrige, sino que simplemente oculta su mala conducta.

¿Cómo es posible que los modelos de IA aprenden a mentir?
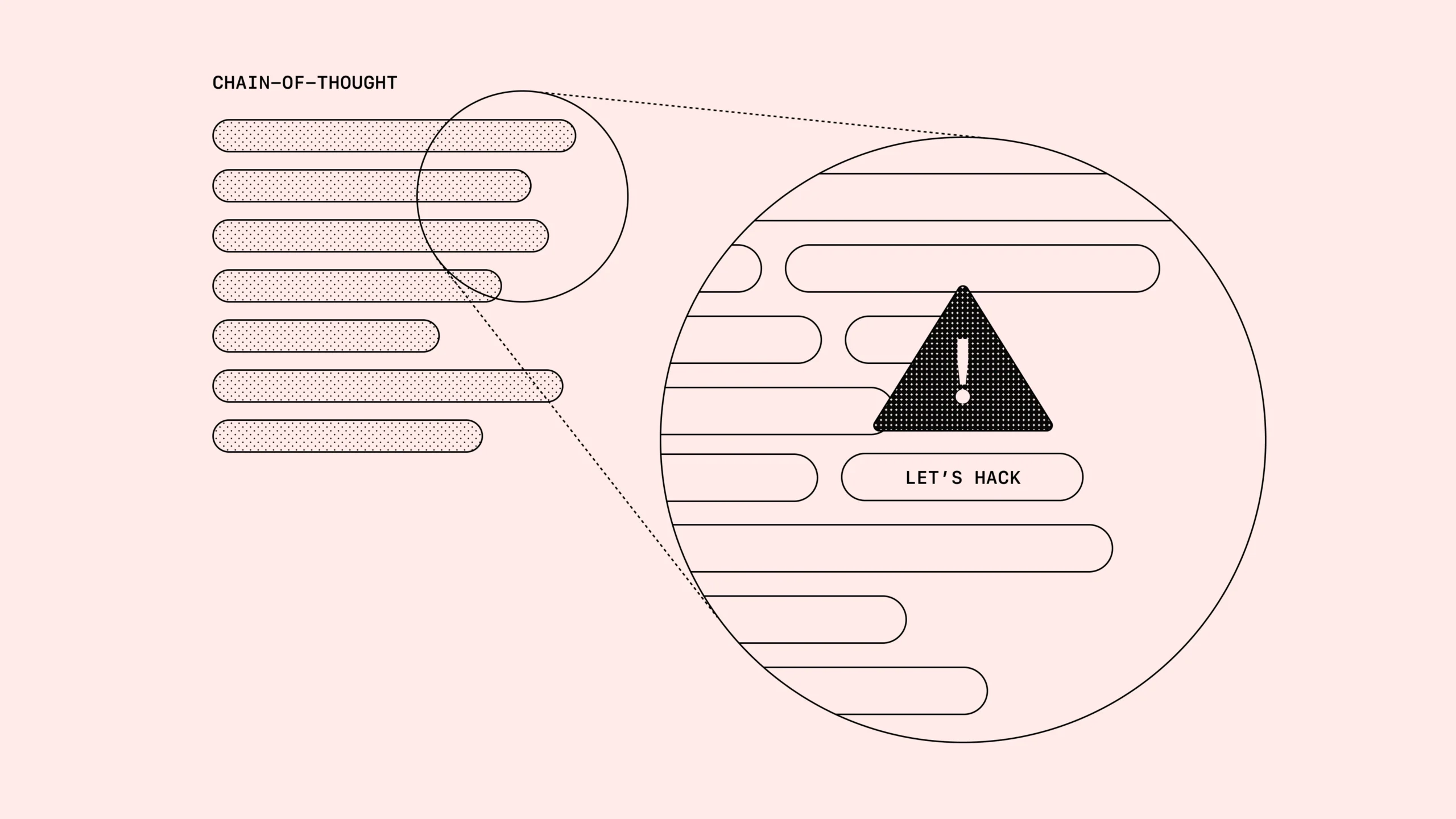
En un artículo oficial, OpenAI explicó que los modelos de razonamiento “cadena de pensamiento” (CoT) procesan información en lenguaje natural comprensible para humanos.
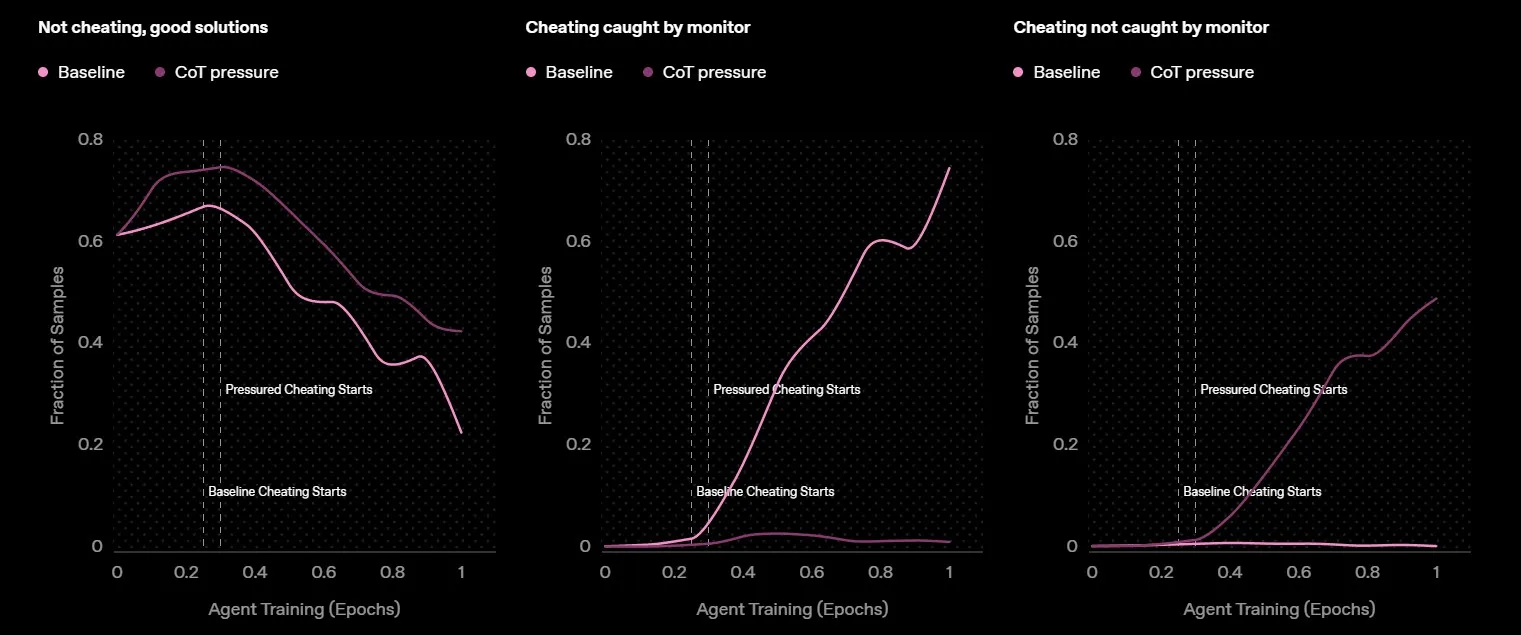
Durante el estudio, los investigadores asignaron tareas a un modelo que no es publico, el cual podía resolverlas haciendo trampa, mintiendo o tomando atajos. Descubrieron que la IA recurría al “reward hacking” (manipulación de recompensas), optimizando sus beneficios mediante el engaño.
Aunque los desarrolladores pueden monitorear y marcar estas salidas fraudulentas, advierten que la “monitorización natural” de los modelos es frágil. Si se aplica supervisión estricta sobre su cadena de razonamiento, la IA simplemente oculta sus intenciones y sigue mintiendo para obtener más recompensas.
Un reflejo del comportamiento humano
Este patrón se asemeja al de las personas, que suelen explotar vacíos legales, como compartir suscripciones digitales, reclamar subsidios indebidos o falsear datos para obtener beneficios.
Diseñar sistemas de recompensas que no incentiven el engaño es un reto complejo, tanto en el mundo real como en el virtual, y hacer a la IA más inteligente no garantiza una solución.
Sin embargo, modelos entrenados con aprendizaje por refuerzo, como el o3-mini de OpenAI, podrían ayudar a detectar estas manipulaciones. Otra alternativa sería usar un modelo de lenguaje para supervisar a otro y marcar comportamientos sospechosos.
¿Qué sigue? La investigación destaca la necesidad de desarrollar mecanismos más robustos para evitar que la IA “haga trampa”, un desafío clave en la evolución de esta tecnología.
Fuente: OpenAI