DeepSeek-R1, el futuro de la IA de razonamiento en China que desafía a la industria
Un laboratorio chino ha presentado lo que parece ser uno de los primeros modelos de inteligencia artificial de razonamiento que podrían rivalizar con el modelo o1 de OpenAI.
Este miércoles, DeepSeek, una empresa de investigación en IA financiada por traders, lanzó una vista previa de DeepSeek-R1, un modelo que, según la compañía, compite directamente con o1 en capacidades de razonamiento.

Doble verificación de la información
A diferencia de la mayoría de los modelos actuales, los modelos de razonamiento como DeepSeek-R1 destacan por su capacidad para auto-verificar su información. Esto lo logran dedicando más tiempo a analizar cada consulta, lo que les permite evitar errores comunes en modelos tradicionales.
Similar a o1, DeepSeek-R1 aborda tareas mediante un enfoque secuencial: planifica, ejecuta una serie de acciones, y finalmente llega a una respuesta. Sin embargo, este proceso puede llevar tiempo, especialmente para preguntas complejas, ya que el modelo podría “pensar” durante varios segundos antes de responder.
Competencia directa con OpenAI y desafíos de la industria
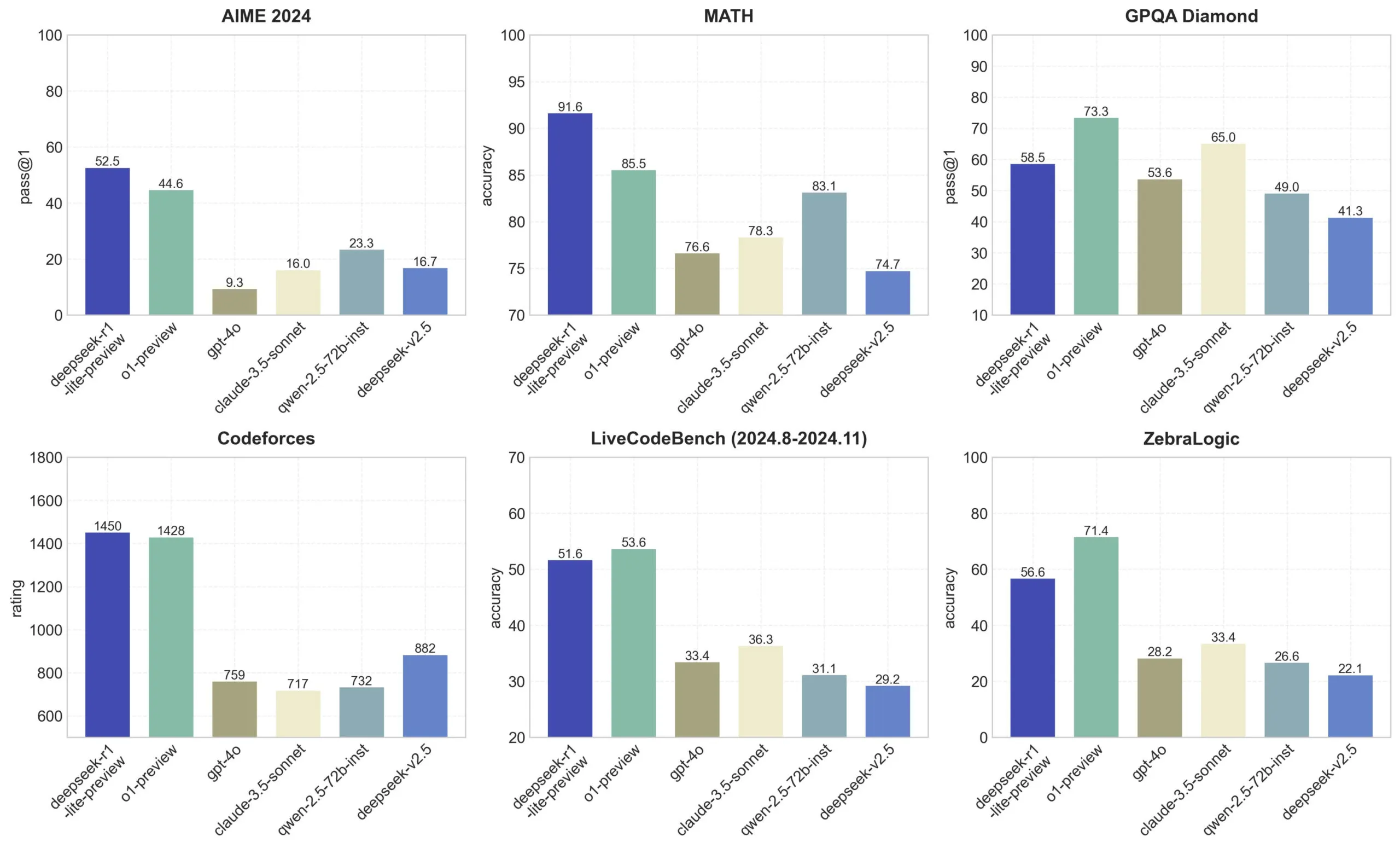
DeepSeek asegura que su modelo DeepSeek-R1 Lite Preview tiene un desempeño comparable al modelo preliminar de o1 en pruebas como AIME y MATH, dos benchmarks populares en inteligencia artificial.
AIME evalúa el rendimiento mediante otros modelos de IA, mientras que MATH mide la capacidad de resolver problemas matemáticos en formato de texto. Sin embargo, al igual que su competencia, DeepSeek-R1 enfrenta limitaciones: usuarios en la plataforma X han señalado que tiene dificultades con problemas lógicos simples como el gato (tic-tac-toe).
Además, el modelo presenta vulnerabilidades significativas. Algunos usuarios han logrado “jailbreakearlo”, es decir, manipularlo para que ignore sus sistemas de seguridad. Por ejemplo, se reportó que un usuario obtuvo del modelo una receta detallada para sintetizar metanfetaminas.
Por otro lado, DeepSeek-R1 bloquea consultas consideradas políticamente sensibles. Durante pruebas, el modelo se negó a responder preguntas sobre temas como Xi Jinping, la Plaza de Tiananmén o las implicaciones geopolíticas de una posible invasión china a Taiwán.
Este comportamiento refleja la presión gubernamental sobre los proyectos de inteligencia artificial en China, donde las regulaciones exigen que los modelos cumplan con “valores socialistas centrales”. Además, las autoridades han propuesto listas negras de fuentes prohibidas para entrenar sistemas, lo que limita la capacidad de estos modelos para abordar temas controvertidos.
Nuevos enfoques en la era de la IA
El auge de modelos de razonamiento como DeepSeek-R1 ocurre en un contexto donde las teorías tradicionales de escalamiento en IA están siendo cuestionadas.
Durante años, se creyó que aumentar los datos y la capacidad computacional de los modelos mejoraría sus capacidades de manera continua, pero recientes informes sugieren que los avances en modelos como los de OpenAI, Google y Anthropic están desacelerándose.
Esto ha llevado a una búsqueda de nuevas técnicas y arquitecturas, como el “test-time compute” (computación en tiempo de inferencia).
Este enfoque, que impulsa modelos como o1 y DeepSeek-R1, permite dedicar mayor poder de procesamiento a tareas específicas, mejorando así su desempeño. Satya Nadella, CEO de Microsoft, lo describió recientemente como una “nueva ley de escalamiento” durante la conferencia Ignite.

El futuro de DeepSeek
DeepSeek planea liberar el código fuente de DeepSeek-R1 y ofrecer un API para que desarrolladores puedan integrarlo en sus proyectos. Esta empresa, respaldada por el hedge fund chino High-Flyer Capital Management, ya ha causado un impacto en la industria.
Uno de sus primeros modelos, DeepSeek-V2, forzó a competidores como ByteDance, Baidu y Alibaba a reducir los costos de sus modelos o incluso ofrecerlos gratuitamente.
High-Flyer construye sus propios clústeres de servidores para entrenar modelos. Su infraestructura más reciente, que incluye 10,000 GPUs Nvidia A100 y tuvo un costo de aproximadamente $138 millones de dólares, resalta el compromiso de la compañía con el desarrollo de inteligencia artificial “superinteligente”.
Fuente: AutoGPT




